CSS Sprite 또는 CSS Image Sprite라고도 불리는데요, 여기서 이 Sprite라는 단어는 합성과 같은 의미로 쓰여지는데요. 직역을 해보자면 CSS 이미지 합치기(?) 가 되겠습니다.
왜 이미지 합치기라고 불리냐면 CSS image Sprite는 여러개의 이미지를 하나의 이미지로 합쳐서 관리하는 기술이기 때문입니다.
이해를 돕고자 친숙한 사이트 몇개를 선정해 실제로 사용중인 Sprite image를 가져왔습니다.
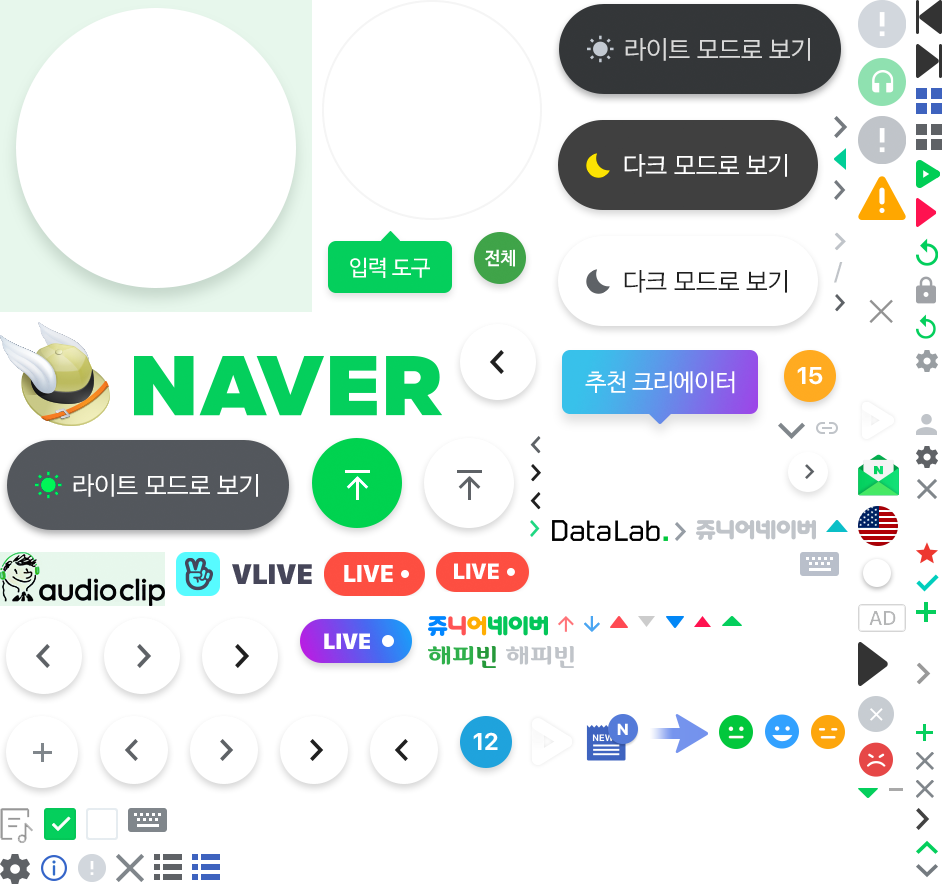
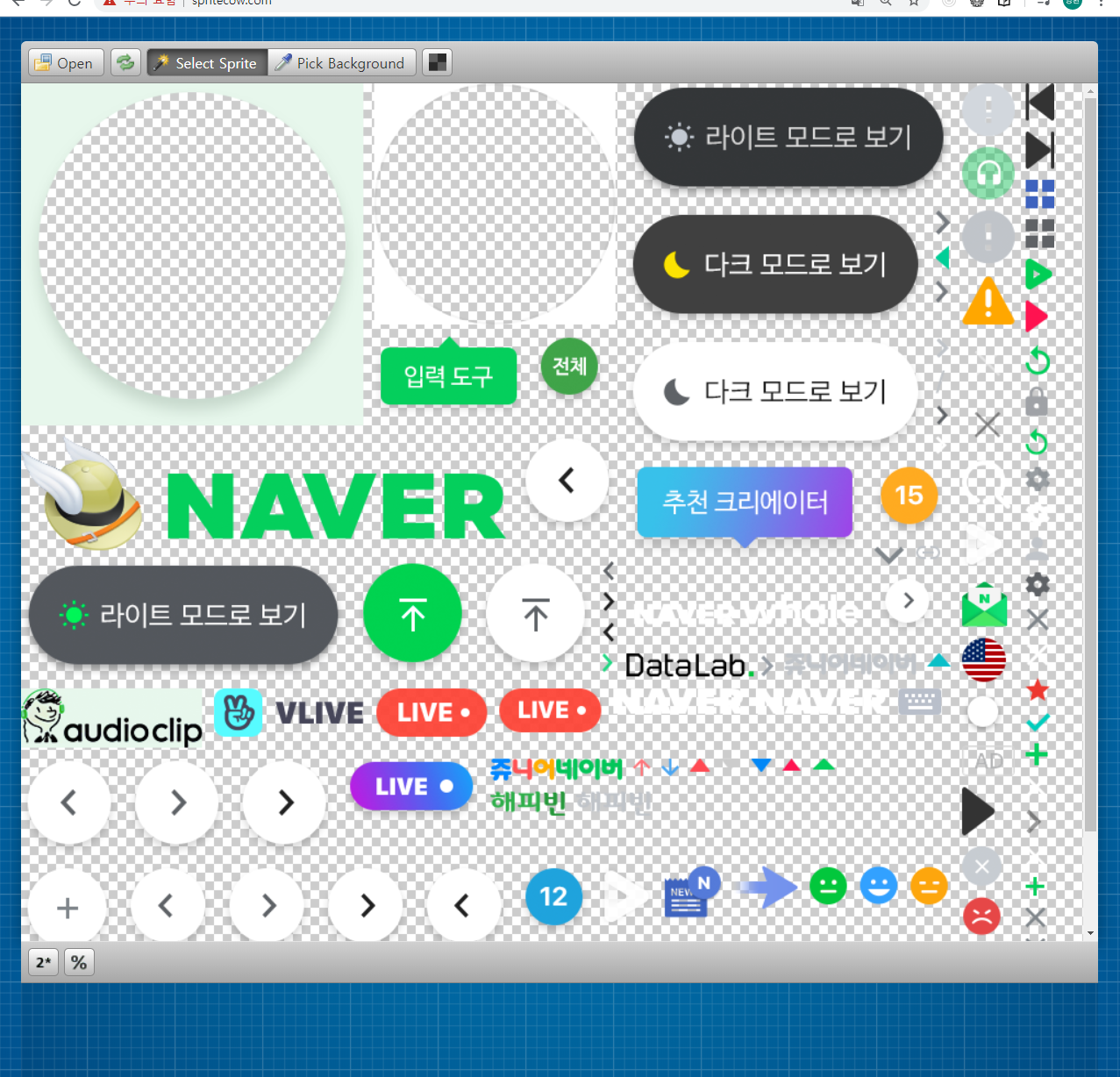
NAVER sprite image
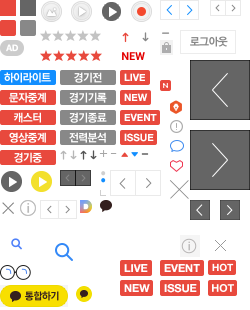
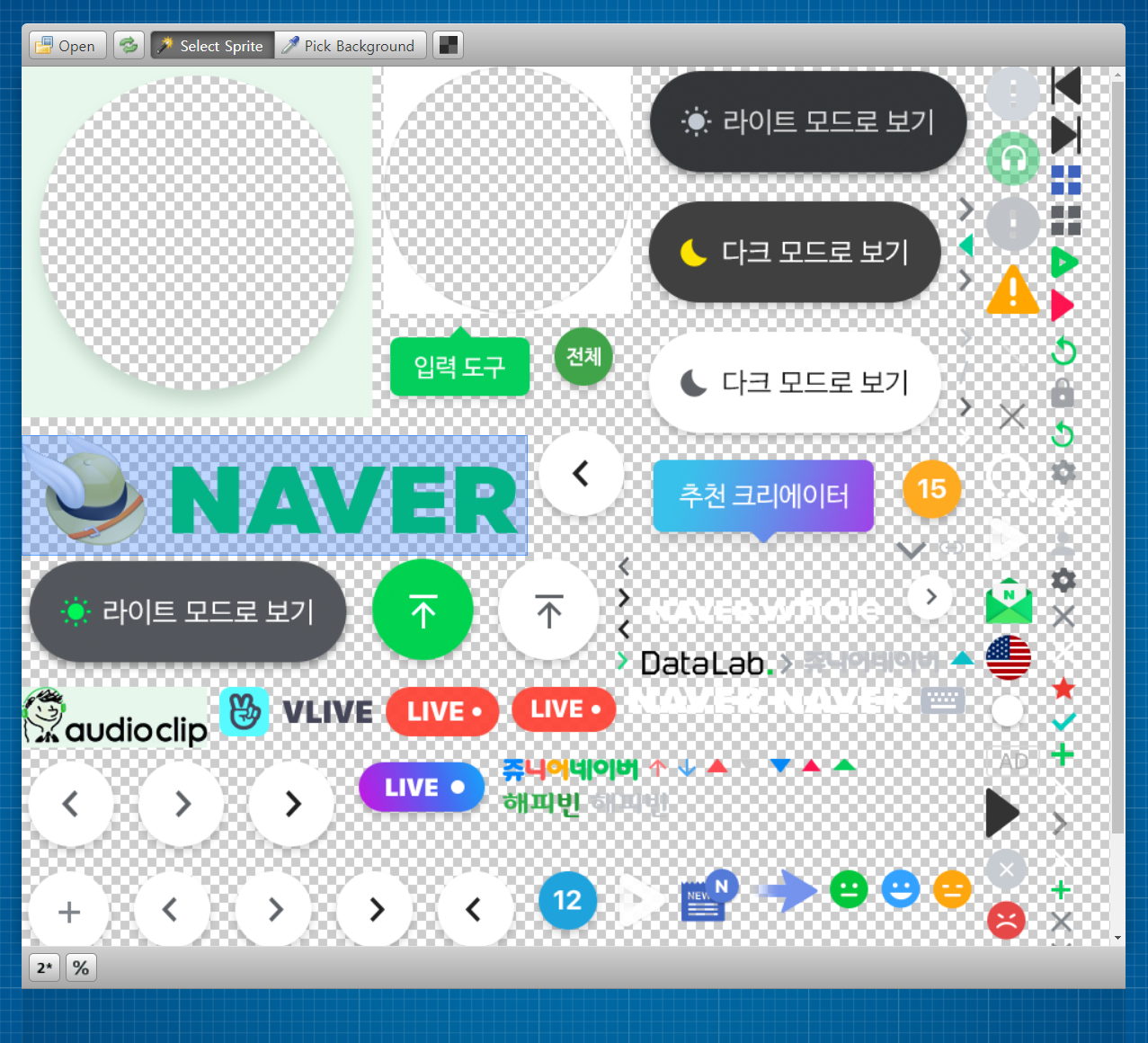
Daum sprite image
두 사진은 각각 네이버와 다음에서 실제로 사용중인 Sprite image 입니다.
🤔철수: "어? 그러면 html에서 image가 하나면 어떻게 불러다 사용해요? 저는 로고 하나만 필요한걸요?"
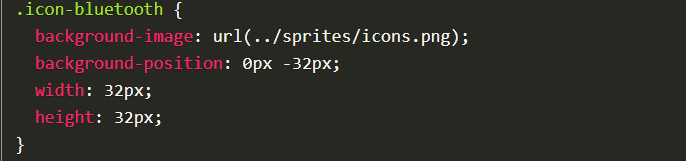
🐵: 다 방법이 있습니다. CSS의 background 속성중에 background-image, background-position 와 우리가 원하는 로고의 크기 즉 width, height 속성만 있다면 Sprite image에서 특정 아이콘 부분만 사용하는것이 가능합니다.
마치 이런식으로 말이죠.
🤔철수: "다시 생각해 보니깐 굳이 이렇게 사용해야 하는 이유가 있을까요? 여러사진으로 보내는게 사용하기 편할꺼 같은데요.
🐵:
이러한 방식으로 사진을 사용하는 이유는 사이트의 성능을 향상시키기 위함인데요. 사실 이전 포스팅에서 iamge spriting에 대해 살짝 언급을 했었습니다.
요약해서 말씀드리자면, 브라우저는 한번에 하나의 파일만 가져올수 있습니다. 그렇기 때문에 이미지 여러개를 요청하게 되면 그만큼 서버로 요청도 많아지게되고 요청이 많아지는 만큼 네트워크 지연도 많아지게 됩니다. 결국 페이지렌더링이 늦어지게 되는거죠.
그렇기 때문에 많은 사이트에서 HTTP 요청 횟수를 줄이기 위해서 로고나 아이콘과 같은 사진들을 하나로 합쳐서(Sprite) 하나의 이미지로 만들어 보내는 것입니다.
이러한 sprite image에서 특정 icon의 위치 찾는게 쉽지만은 않습니다. 그래서 이러한 sprite image 에서 특정부분을 사용하기 위한 css로 바꿔주는 여러 프로그램과 사이트들이 있는데요. 제가 소개드릴 사이트는 sprite cow 라는 사이트입니다. http://www.spritecow.com/
사이트에 들어오셔서 원하는 이미지를 열어줍니다. 저는 네이버의 sprite image를 열었습니다.
그리고 마우스를 이용해 원하는 로고영역을 선택해주세요.
그러면 아래에 해당 영역을 사용하기 위한 css가 나타내어지게 됩니다.
오늘 살펴볼 내용은 여기까지이구요. 궁금한점이나 피드백은 언제든 환영입니다. 댓글을 통해서 의견 남겨주시길 바랍니다 : ) 감사합니다.
프로그레시브 렌더링은 서버에서 웹 페이지의 일부를 순차적으로 렌더링하면서 전체 페이지가 렌더링 될 때까지 기다리지 않고 웹 페이지를 클라이언트에 스트리밍하는 기술입니다.
즉, 콘텐츠를 가능한한 빠르게 표시하기 위해서 사용이 되는데요. 이를 이해하기 쉽게 하나의 예를 들어 보겠습니다.
🤔 철수 : "다른 사이트랑은 다르게 네이버는 메인 페이지에서 엄청나게 많은 데이터를 보여주고 있는데, 뭔가 더 빠르게 페이지가 로드되는거 같아"
🐵:
위의 철수의 사례가 이해하기에는 대표적인 사례가 아닐지 싶습니다. 네이버같은 경우에는 메인페이지에서 보여주어야할 데이터가 정말이지 많습니다. 광고부터 뉴스 그리고 실시간검색까지 정말이지 많은 데이터를 받아오는데요. 이때 우리는 기타 다른 사이트와 동일한(?) 대기시간을 느낍니다. 그 이유는 네이버도 progressive rendering을 사용하고 있기 때문이라 볼수 있습니다. 네이버도 중요한 데이터를 먼저 받아와 랜더링하고 그 다음 덜 중요한 순으로 데이터를 보내주어 화면을 랜더링해주고 있기 때문입니다.
눈에는 보이진 않지만 뒤에서 열심히 데이터를 받아 바로바로 화면에 보여주고 있는것이죠
점진적 렌더링 (일명점진적 서버 측 렌더링)은서버에서 중요한 컨텐츠를렌더링 한 후에 중요하지 않은 컨텐츠를 기다리지 않고 클라이언트로 스트리밍을 시작하는 기술입니다.
그런 다음 중요하지 않은 콘텐츠는 나중에 서버에서 렌더링되면 스트리밍합니다. 브라우저는 중요한 내용에 대해 먼저 렌더링을 시작하여 브라우저 화면에 그려줍니다. 그다음 브라우저가 서버로부터 컨텐츠를 수신하면 중요하지 않은 컨텐츠는 나중에 페이지에서 렌더링 (페인트)됩니다.
이 과정을 절차적으로 확인해 보도록 할게요.
브라우저가 서버에 HTML을 요청합니다.
서버는 API 요청을 수행하고 서버에서 중요한 컨텐츠를 먼저 렌더링하여 브라우저로 스트리밍합니다.
브라우저는HTML청크(덩어리)를 받아서 화면에 렌더링 (페인트)합니다.
서버는 중요 컨텐츠를렌더링한 후중요하지 않은 컨텐츠를렌더링하고이를 클라이언트로스트리밍합니다.
브라우저는 나중에 중요하지 않은 컨텐츠를 받아서 렌더링 (페인트)합니다.
전체 페이지가로드되면 브라우저는 일반적으로 이벤트 핸들러 및 기타 대화식 동작을 연결하는 DOM 요소에 대한 상호 작용을 수화합니다.
다음은SSR vs PSSR로렌더링 된 동일한 웹 사이트의 예입니다.사이트가 대기 시간이 긴 저 대역폭 네트워크를 통해로드되었다고 가정합니다.
Pers프로파일 링SSR과 PSSR을비교하면 페이지에 컨텐츠가 얼마나 빨리 표시되는지 명확하게 개선 할 수 있습니다.
이미지 지연 로딩 - 페이지의 이미지를 한꺼번에 로딩하지 않습니다. JavaScript를 사용하여 사용자가 이미지를 표시하는 페이지 부분으로 스크롤 할 때 이미지를 로드 할 수 있습니다.
보이는 콘텐츠의 우선순위 설정 (또는 스크롤 없이 볼 수 있는 렌더링) - 가능한 한 빨리 표시하기 위해 사용자 브라우저에서 렌더링될 페이지에 필요한 최소한의 CSS/콘텐츠/스크립트 만 포함하면deferred스크립트를 사용하거나DOMContentLoaded/load이벤트를 사용하여 다른 리소스와 내용을 로드할 수 있습니다.
오늘 포스팅할 내용은 브라우저가 서버로부터 데이터를 받아 사이트를 로드시키기까지 걸리는 시간에 대하여 이야기를 해보고자 합니다.
😧철수 : "한국장학 재단 사이트에 접속을 하는데 브라우저에서 사이트 화면이 나오기 까지 잠시 화면이 흰바탕 화면으로 보였어!"
🐵:
네 아주 자연스러운 일인데요, 우리가 특정 사이트를 접속할 때 종종 잠시 흰바탕의 화면이 나오는것을 볼 수 있습니다.
한국장학재단 사이트 접속중 캡쳐
이러한 화면이 나오는 이유는 서버로부터 보내진 Html, Css, Js, jpg... 등 파일들이 아직 브라우저로 도착하지 않았기 때문에 발생하는 현상입니다.
즉, 화면에 보여줄 데이터가 없어서 발생한거에요.
그리고 이러한 화면이 사라지기까지의 시간을 '페이지 로드시간' 혹은 '레이턴시', 대기시간 등으로 불립니다.
😧철수 :그렇다면 이러한 대기시간을 줄이는 방법은 무엇이 있나요?
🐵:
일단 현재 대기시간을 줄이고자 하는 서비스의 형태에 따라 답변이 달라질 수 있을것 같습니다.
만들어진 웹서비스가 SSR 즉 서버측에서 화면을 모두 구성한 다음에 보내주는 방식의 서비스인가 또는 CSR 이라고 클라이언트 측에서 서버로 부터 데이터를 받은 후에 이를 가지고 화면을 구성을 하는가에 따라서 이러한 '대기시간'의 등장 빈도수가 달라집니다.
일반적으로 SSR을 따르게 되면 페이지에서 페이지로 이동시 전체문서 즉 Html 부터 CSS, JS까지 다시 요청해서 받아오게 됩니다. 그렇기 때문에 페이지 이동간에 '대기시간'이 계속 나타나게 되어지죠.
하지만 CSR을 따르게 되면 최초에 화면을 구성하기 위한 데이터를 받아오고, 이후 페이지 이동간에는 필요한 최소한의 데이터만 서버로부터 받아와 화면을 구성하기 때문에 SSR과는 다르게 '대기시간'이 매우 짧아지게 됩니다.(거의 안느껴지죠)
이렇듯 서비스 전체에 대한 총 대기시간을 줄이고자 하는것이 목적이라면 이렇게 CSR형태로 개발하는 방법이 답이될 수 있겠습니다.
😧철수 : 그렇다면 CSR로 개발하면 무조건 효율적인건가요?
🐵:
그렇지 않습니다.
사실, CSR은 초기 도입시에 대한 대기시간(페이지로드시간)이 SSR형태의 서비스에 비해 깁니다.
그 이유는 CSR이 화면을 구성하기 위한 데이터를 미리 다 받아두고 이후 페이지 변화간에 기존에 받아두었던 데이터를 재 활용해서 화면을 구성해주기 때문입니다. 미리 데이터를 다 받아두기 때문에 서버로 부터 받는 데이터 크기 또한 다를 뿐더러 화면을 구성하기위해 JS코드를 해석하는등 이러한 추가적인 시간이 생기게됩니다.
이러한 상황에서는 우리가 최초 페이지 로드시간을 줄이는 방법은 여러가지가 있습니다.
일단 개발자를 이용한 개선방법부터 알아보겠습니다.
받아온 데이터를 해석하는데 걸리는 시간을 줄이기 위해서 평소 개발시 불필요한 코드를 정리하는 습관을 들이거나, 최대한 심플한 코드를 짜는 습관을 들이는 방법이 있겠습니다.
다음은 네트워크 측면에서 방법을 찾아보겠습니다.
서버로부터 보내진 데이터를 받기까지의 걸리는 시간 때문에도 대기시간이 생깁니다. 이러한 상황은 서버로부터 데이터를 빠르게 받는 방법을 통해 대기시간을 줄일 수 있는데요.
그 첫번째 방법으로는 단순하게 네트워크 속도 그 자체를 빠르게 만들어 주는겁니다. 하지만 이러한 방법은 개발측면에서 할 수 있는것이 아니기 때문에 쉬운 방법은 아닙니다.
두번째 방법으로는 서버로부터 보내는 데이터를 최대한 작게 만들어서 보내주는 방법이 있습니다. 개발이 완료된 소스코드의 들여쓰기나 빈 여백공간과 같이 소스코드 열람시 개발자의 가독성을 위한 데이터 부분들을 제거하는 등 소스코드 자체를 압축시키는 방법이 있습니다.
세번째 방법으로는 gzip을 이용한 전송데이터 압축인데요. 전송하고자 하는 데이터를 압축시켜서 전송시켜주고 이를 클라이언트가 받아서 압축을 풀어 사용하는 방식입니다. 이 방식은 데이터 크기 자체를 줄여 전송시켜주기 때문에 도착까지 걸리는 시간이 적습니다. 하지만 클라이언트가 압축을 해제후 사용해야 하기 때문에 크기가 다소 작은 데이터를 보낼때는 효율이 좋지 않을 수 있습니다.
CRA를 이용하여 React 프로젝트를 생성 후 실행하게되면 localhost:3000번으로 React 서버가 실행이 되어집니다. 그리고 같은 컴퓨터에서 서버를 개발하여 실행후 방금 만든 React 서버와 데이터를 잘 주고받나 테스트를 진행해야 하는데, 이때 이미 3000번 포트는 React 서버가 사용하고 있으니 서버는 다른 포트번호를 사용해야 합니다.
그래서 저는 보통 서버는 4000포트를 사용하고 있는데요. 이때 React서버에서 자신의 포트와 다른 4000번 포트(서버)로 특정 데이터(자원)를 요청해야 하는데, 이때 CORS가 밸생하게 됩니다. (다른 포트로 자원을 요청하니깐요!)
이러한 경우에는 request 객체의 header에 "Access-Control-Allow-Origin" 옵션을 추가해 주시면 됩니다.
📌 CORS Middleware 사용하기
모든 request마다 CORS를 위한 "Access-Control-Allow-Origin" 옵션을 추가하기는 어렵기 때문에 Node의 cors라는 미들웨어를 사용하여 이를 처리합니다.
npm 이나 yarn을 이용해서 설치합니다.
npm install --save cors
yarn add cors
그리고 express 서버 파일에서 다음과 같이 입력함으로서 쉽게 CORS를 허가해줄 수 있습니다.
const express = require('express');
const cors = require('cors');
const app = express();
app.use(cors()); // CORS 미들웨어 추가
...
하지만 앞서서 이야기를 드렸지만 브라우저가 CORS를 막는 이유는 보안상의 이유입니다. 이렇게 모든 요청마다 CORS를 허가해준다면 보안상으로 문제가 많아지게 됩니다.
이러한 이유로 React를 이용한 개발을 진행할때는 이런 방식으로 개발을 진행하는 것 보다는
"webpack-dev-server proxy" 기능을 사용하여 서버쪽 코드를 수정하지 않고 해당 이슈를 해결하는것이 바람직합니다.
❗❗ ) 본 포스팅 내용은 면접에서 받은 질문을 통해 스스로에게 부족한 점들을 찾고, 그를 보완해 나아가기 위하여 작성하였습니다. 이 글을 통해서 저와같이 면접을 준비하시는 뉴비 개발자들께도 도움이 되었으면 합니다.
✅ 하계 채용 연계 국가근로 인턴쉽
반갑습니다. 개발자를 꿈꾸는 김고릴라입니다. 오늘은 제가 정보처리기사 시험과 함께 준비했었던 기업의 면접을 다녀왔습니다. 너무 긴장을 했었는지 끝나자마자 힘이 쫙 빠져서 아무것도 할 수 없겠더라구요...😂. 그래서 오늘은 제가 어떻게 인턴을 하게되었고, 어떤 프로세스로 진행이 되는지에 대하여 이야기를 해보려고 합니다.
🌈 목차
인턴을 준비하다.
채용절차와 특이점.
실무진 면접.
📘 인턴을 준비하다.
저는 최대한 학교와 연계되어있는 인턴쉽을 활용을 하려고 노력하는 편이랍니다. 제가 소속되어있는 학교에서는 이러한 학교연계인턴을 "현장실습"이라고 부르고, 이러한 일들을 처리하는 부서가 따로 존재하고 있습니다. (가이드가 담긴 책도 있어요) 저는 ICT 학점연계 인턴쉽만 알고있었는데, 우연히 "하계 채용 연계 국가근로 인턴쉽"과 관련한 포스터를 보게 되면서 지원하게 되었답니다.(개이득!)
대학교 4년다니면서 처음봤을리가 없을것이다... 생각하고 작년에도 시행했었나 찾아보니깐 매해 꾸준히 시행하던 인턴쉽이더군요 ㅋㅋㅋㅋ 만약 이글을 보신 분들께서는 한번 학교 공지사항등을 잘 찾아보시기 바랍니다!! (저처럼 되지 마세요..!)
📘 채용절차와 특이점.
이 인턴쉽의 프로세스는 아래 사진과 같습니다.
어떻게 보면 일반 인턴쉽과 비슷하다고 생각할 수도 있는데 조금 특이한 사항들이 있어서 그 이야기를 지금부터 해볼까 합니다.
일단, 새롭게 알게된 이 인턴쉽 프로그램에서는 이 행사에 참여하는 기업들의 리스트가 담긴 엑셀 파일을 하나 제공해줍니다. 그리고 지원을 하기 위해서는 일반 인턴쉽과 마찬가지로 자소서를 제출해야 했죠. 여기서 특이하다고 생각했던것이 2가지가 있었는데요. 아래 정리를 통해 설명드리겠습니다.
(지금부터 작성될 내용은 저의 모교대학에만 국한된 이야기일수도 있으니 글을 잘 확인하신 후에 학교에 연락을 취하셔서 잘 확인해 보시길 바랍니다. )
기업목록중 단 한회사의 한부서에만 지원이 가능하다.
서류평가는 학교에서 진행한다..(?)
일단 첫번째부터 설명드릴게요. 일단 기업목록이 담긴 엑셀표를 받으면 IT 회사 그리고 IT관련 부서만 있는것이 아니라 정말 다양한 직종의 회사 및 부서들이 있습니다. 각 회사마다 원하는 인재조건들이 제시되어있고 복지 및 채용후 혜택에 대한 정보또한 명시되어있습니다. 그래서 이 인턴쉽에 지원하는 학생분들께서는 잘 살펴보시고 자신과 잘 맞는 기업의 부서를 선택해 지원하면 되는데요. 그런데 여기서 원하는 기업이 여러개가 있더라도 무조건 단 한 기업의 한 부서만 신청이 가능하다는 제약 조건이 있었습니다.
기회가 단 한번뿐이기 때문에 높은 회사를 지원하는것도 좋겠지만 적절히 합격여부와 잘 타협하여 기업을 선택하시길 추천드립니다.
(사실 저같은 경우에는 이런거 안따지고 가고싶은 회사를 지원했습니다 ;D )
두번째는 서류평가 관련인데요. 기업 복수지원과 관련하여 문의하고자 학교측에 연락을 취했었는데 이때 상담사(?) 담당자(?) 분께서 재미있는 이야기를 해주셨습니다. 그건 바로 서류를 학교측에서 평가를 한다는 이야기였습니다. 학교측에서는 지원된 자소서를 평가한 뒤에 합격여부를 정하고 합격된 자소서는 해당하는 기업에 발송하는 형식으로 진행이 된다고 이야기를 주셨습니다. 일반적인 인턴쉽이랑은 조금 다르구나 생각했었는데, 이후에 이런 말씀도 같이 주셨습니다. "물론 서류평가를 학교에서 하나 원하는 기업에 한에서는 자체적으로 2차 서류평가를 할수도 있고 코딩테스트와 같은 테스트도 볼 수 있습니다." 이말을 듣고 결국 기업에서 서류평가를 하기 때문에 대충 썻다가는 칼같이 떨어질수도 있겠구나 생각하고 정말 열심히 자소서를 썼던 기억이 납니다... 물론 여담이지만, 다른 기업에 지원서를 넣었던 선배는 2차 서류평가가 없었다고 해요! (심지어 면접도 안봤다는..? 응..?) 하지만 저의 경우에는 2차 서류평가도 꼼꼼히 이루어졌었구요, 면접또한 실무진 두분과 함께 했습니다.
일단 자소서를 제출과 마감기한이 끝나고 나서 한 1주일(?) 정도 기다리니깐 학교측으로부터 서류평가(저한테는 1차서류)가 합격 되었다는 문자를 받을 수 있었습니다. 그렇게 저의 자소서는 제가 원하던 기업 인사담당자분께 전달이 되었고 그렇게 1주일 조금 안되게 기다리니깐 2차서류평가에 합격했다는 메일을 받을 수 있었습니다. 그 후에는 기업측에서 피면접자를 배려하여 면접 날짜와 시간을 조율해 주셨고 정해진 날짜인 오늘..! 2020. 06. 12에 면접이 이루어졌습니다.
📘 고릴라.. 첫 면접을 보다.
이번 인턴준비와 면접은 저에게 아주 뜻깊은 시간인데요. 뭐 딱히 거창한 이유는 없지만, 흐흐흐 제가 처음 해보는 일들이기 때문입니다😉. 일단 저의 면접은 실무진 면접이 진행된다고 메일로 말씀을 주셨습니다. 처음 이 메일을 받았을때 정말 멘.붕. 이었어요.
"실무진 면접이면 전문가들이 면접을 진행하겠지? 그러면 엄청 기초적인 질문부터 어려운 질문까지 할꺼같고... 면접까지는 대략 1주일정도 남았으니깐... 허허허... 뭐부터 해야하나...😂😂😂"
ㅁㄴㅇㄻㄴㅇㄹ 안그래도 캡스톤, 정보처리기사, 졸업준비 등 바빠죽겠는데 이 와중에 면접준비를 해야만 했습니다. 그래도 뭔가 저의 목표 그리고 이상향과 잘 부합되는 기업이었어서 놓치고 싶지 않은 마음이 더 컸던거 같습니다. 그래서 시간을 더 투자해서 밤낮으로 기초나 면접공부를 했던것 같습니다. 그래도 다행이었던건 해당 기업에 관심이 많았던 탓에 자주 검색하면서 찾아봤던 것들이 기업분석하는 시간을 대폭 줄여주었습니다.
암튼! 결전의 면접날(=오늘)이 왔고, 오후 2시에 면접이 진행되었습니다. 사실 한시간이나 일찍가서 회사 구경도 좀.. 하고 싶고 그랬는데, 제가 도착한 시간이 점심시간이라 그랬는지 직원분들이 로비에 너무 많았습니다. 원래 이런 성격이 아닌데ㅋㅋㅋ 다들 쳐다보는 눈빛에 기가 죽었는지 ㅋㅋ 조용히 앉아서 공부를 했네요 ㅋㅋㅋㅋ.
그렇게 2시가 되니깐 인사팀원(?) 분께서 저를 면접이 진행될 소회의실로 안내를 해주셨고, 본격적인 면접이 시작되었습니다. 저는 실무진 면접이 진행이 된다 사전에 이야기를 해주었기 때문에 O개발팀에 팀장님과 ㅁ팀의 개발자 분께서 면접을 진행해 주었습니다.
처음 보는 면접이라 면접관님들 들어오자마자 자리에서 벌떡 일어나서 90도 인사를 했네요 허허.
이제 제 궁상맞은 이야기는 잠시 멈추고, 가장 궁금해 하실 면접질문에 대해서 말씀을 드릴게요!
제가 우려했던것과는 다르게 실무진 면접동안 어려운 기술질문은 2개? 정도 들어왔던것 같아요. 대부분 자소서 기반에 있는 내용을 질문을 해주셨구요. 기술질문은 자소서 안에 작성했던 프로젝트나 개발관련 이야기를 보시고 그와 관련된 기술질문을 주셨어요. 다행히 자소서를 부풀려서 적었다거나 거짓된? 스토리를 담지 않아서 제가 경험했던 이야기를 있는 그대로 말씀을 드렸답니다. 대신에... 테스트.. 프로그램 Validation&Verification 절차를 진행해본 경험.... 등에 대해서 질문을 주셨고 그와 관련된 2가지 질문을 더 주셨습니다. 뭐랄까 이론으론 잘 알고있는데, 실제로는 등한시했던 부분인데, 약점을 정확히 공략당한 기분이었습니다 ㅋㅋㅋㅋ 부끄럽네요... 네.. 공부하겠습니다.
면접진행은 최대 1시간 30분동안 진행된다고 했던것에 비해 정확히 56분만에 끝이 났습니다. 뭐랄까 1시간을 못채워서 아쉬운 느낌이었던것 같아요. 뿐만 아니라 원래 긴장하고 떠는 성격이 아닌데 면접때는 엄청나게 긴장이 되었던것 같습니다. 그래도 멘탈 휘어잡고 차분하게 답변을 이어나갔던것 같아요. 추가로 이 기억이 진실이 아니었음 하지만 ㅋㅋㅋ 제가 몇몇 답변을 너무길게 했던것 같은 기억이 있어요. 이글을 보시는 분들께서는 저와같은 실수를 하지 않기를 바라겠습니다.
아직 결과는 나오지 않았구요, 그거는.. 저도 궁금하네요🤔
여기까지 이번 인턴을 준비하면서 느낀점과 그 절차에 대한 후기였구요. 다음 포스팅에서는 합격했어요! 라는 주제로 다시 만나길 기대합니다.ㅋㅋㅋ
이틀전에 드디어! 정보처리기사 필기시험을 무사히 치루고 왔습니다!🐵🐵 시험이 밀리고 밀린지라 빠르게 시험신청을 했음에도 불구하고 제가 거주하고 있는 지역에서 시험을 보지 못했어요.. 그래도 커피 두잔을 부랴부랴 챙겨들고 아버지의 도움을 받아 시험을 보러 다녀왔습니다 :D
일단 시험을 처음 받아서 검토를 할때 스윽~(느낌아시죠?)보니깐 개정후 1회차 시험이라 그런건지 어려운 문제를 쉽게 발견하지는 못했습니다. 그리고 시험이 시작하고 문제를 막 후다닥 풀기 시작하는데 시험시간이 2시간30분인거에 비해 저는 1시간만에 모두 풀 수 있었습니다. 제가 체감한 난이도는 상중하에서 중하~하 정도 였고, 이건 전공자분이신지 비전공자분이신지에 따라서 다를순 있을것 같았습니다. 과거 정보처리 기능사를 땄을때와 비교를 해보자면 일단 과목들 자체가 일반 컴퓨터공학 전공의 모든 커리큘럼이 담겨져 있다 봐도 될정도로 범위가 넓어졌고, 실무적인 관점에서도 이전보단(?) 도움이 되는 내용들로 채워져 있었습니다. 만약 비전공자분이시라면 2020년도 이전에 시험을 준비할때 필요했던 시간보단 더 많은 시간을 투자해야 할꺼같습니다.
저는 2020시나공 정보처리기사 필기책을 가지고 공부를 진행했는데요, 공부할때는 꽤나 내용을 탄탄하게 담아놓은 책인지라 외워야할 내용이 많았습니다. 공부방식은 매일 100Page씩 학습하고 책을 3회차까지 반복해서 보고 시험을 치뤘습니다. 총... 21일? 정도 준비했던것 같습니다. 일단, 이게 제가 가능했던 이유는요... 저는 컴퓨터를 전공했기 때문에 조금 복잡하거나 어려운 내용이 나와도 이미 한번 학습한걸 복습하는 느낌으로 이해하고 넘어갈 수 있었기에 가능했습니다. 만약 [소프트웨어공학, 네트워크, 운영체제, 절차언어, 객체언어, 데이터베이스] 이들을 배워본적이 없거나 처음 보신 분들은 저보다는? 더 시간을 투자하셔야 할듯 싶습니다.
이제 이번 시험문제에 대해서 이야기를 진행해 보겠습니다. 제가 비교적 쉬운 난이도라고 말씀을 드렸었습니다. 그런데,, 쉬웠지만 문제는 과목1(소프트웨어설계)에서 발생했습니다. 다른 과목들은 거의 책에 있는 내용을 기반으로 나왔기 때문에 별다른 문제없이 술술 풀렸지만, "소프트웨어 설계"과목에서 책에서 보지 못했던 내용들이 조금 있었습니다. 물론 다른 과목에서도 "뱅커스알고리즘"과 같이 책에서 다루지 않은 내용이 있었습니다.(과거의 전공공부 지식을 꺼내느라 힘들었습니다...) 그래도 큰 걱정을 하지 않으셔두 될꺼같은게 공부를 성실히 하셨다면 앞서서 말씀드린 문제들은 소수에 불과하기 때문에 합격에는 큰 영향을 미치진 않을꺼 같습니다. 또, 전공자분이시라면 저처럼 뇌를 짜내어서 과거의 기억을 더듬다 보면 적절히 대처해서 풀 수 있으리라 생각이 드네요.
이제 정보처리기사 취득에 반을 왔는데요, 앞으로도 실기를 열심히 준비해서 다음에는 자격증 취득 후기로 돌아오겠습니다 ; )
📘 HTML 강의수강시작!
오늘부터 "닥코"님의 HTML 수업이 시작되었습니다. 클래스톡이라는 서비스에서 진행이 되었는데 지금부터 기타 온라인 강의에 비해 좋았던 점들을 말씀드리도록 하겠습니다.
첫번째로, 수강이 시작이 되어지면 학습을 함께하는 그룹을 만들어 줍니다. 그룹안에서 내가 공부를 얼만큼 했는지도 확인이 가능하고, 더 나아가 그룹원들과 소통할 수 있는 공간이 마련이 되어있어서 다른 강의 사이트에 비해 의욕이 더 솟는것 같아요.
두번째로, 강의마다 미션이 존재합니다. 이건 타 강의사이트에도 종종 볼 수 있는 시스템인데요. 당근과 채찍에서 당근이랄까요? 열심히 강의를 듣고 미션을 클리어하고 추가로 그룹원들과 소통을 많이 할수록 포인트를 많이 쌓을 수 있습니다. 여기서 이 포인트에 따라서 추후 환급해주는 시스템이 갖추어져 있어요.
세번째로, 기초에만 다루는 강의 내용이 아니라 조금 더 실무관점에서 내용까지 같이 다뤄주는 "닥코"님!이 계십니다. 아직은 강의를 많이 듣지 않아서 더 정확한 리뷰는 나중에 따로 진행하도록 할게요!
오늘은 자바스크립트 안에서 스코프라는 용어와 호이스팅이라는 용어에 대해 공부하는 시간을 가져보도록 하겠습니다.
Scope(스코프) 단어 그자체를 직역하면 범위라는 의미를 가지고 있습니다. 그럼 자바스크립트에서 말하는 Scope는 어떤 범위를 의미하는 것일까요?
프로그래밍에서는 변수나 함수에 이름을 부여하여 의미를 갖도록 하고있습니다. 만약 이름이 없다면 변수나 함수는 그저 메모리 주소에 지나지 않게되겠죠. 그래서 프로그램은 "이름: 값"의 대응표를 만들어 사용합니다. 이 대응표의 이름을 가지고 코드를 보다 쉽게 이해하고, 또 이름을 통해 값을 저장하고, 다시 가져와 수정합니다.
초기 프로그래밍 언어는 대응표를 프로그램 전체에서 하나로 관리했었는데, 여기에서 중복된 이름들 간에 이름 충돌의 문제가 발생했습니다.
(전통적인 방식인 var 변수형 타입을 이용하여 선언했다면, 문법적으로 오류가 발생하지 않고 두 번째 나오는 변수가 첫 번째 변수를 덮어쓰여지게 됩니다. 즉 중복된 변수들간에 충돌이 일어난 상황입니다.)
// 호이스팅 문제 발생!
var test = "this is test";
var test = "I am test too!";
(아래의 소스코드는 이러한 중복된 이름으로인한 충돌을 해결한 블록레벨 변수를 사용하여 아래와 같은 상황이 발생하면 문법적으로 오류를 발생합니다. )
// 잘못된 소스코드
let test = "this is test";
let test = "I am test too!";
그래서 충돌을 피하기 위해여 각 언어마다 "스코프"라는 규칙을 만들어 정의를 하였고 여기서 자바스크립트(ES6)는 함수레벨과 블록레벨 의 렉시컬 스코프 규칙을 따르고 있습니다.
[스코프 레벨]
자바스크립트는 전통적으로 함수 레벨 스코프를 지원해왔고, 얼마 전까지만 해도 블록 레벨 스코프는 지원하지 않았습니다. 대표적으로 함수 레벨 스코프인 var만 사용해 왔었죠. 하지만 가장 최신 명세인 ES6(ECMAScript 6)부터 블록 레벨 스코프를 지원하기 시작했고 여기서 나온것이 let 과 const 입니다.
[함수 레벨 스코프 & 블록 레벨 스코프]
자바스크립트에서var키워드로 선언된 변수나,함수 선언식으로 만들어진 함수는함수 레벨 스코프를 갖습니다. 즉, 함수 내부 전체에서 유효한 식별자가 된다는 이야기죠.
함수 내부 전체에서 유효하다는 의미는 반대개념인 블록개념과 비교하여 이해하면 쉽습니다.
블록레벨 스코프들은 블록안에서만 유효한데, 이를 쉽게 설명한것이 지역변수 입니다. 지역변수는 특정 블록안에서만 사용할 수 있는 변수인데요, 해당 지역(블록)을 벗어나면 소멸하여 상요할 수 없는것이 특징입니다. 하지만 함수레벨 스코프를 가지는 함수들은 특정 함수내에서 선언이 되었다면 그 장소가 if문 안이든 While문 안이던간에 그 지역(블록)을 벗어나도 해당 변수를 재 사용하는것이 가능합니다.
[렉시컬 스코프]
그렇다면 렉시컬 스코프란 무엇인가?
렉시컬 스코프(Lexical scope)는 보통 동적 스코프(Dynamic scope)와 많이 비교합니다.
동적 스코프는 프로그램의 런타임 도중의 실행 컨텍스트나 호출 컨텍스트에 의해 결정되고,
렉시컬 스코프에서는 소스코드가 작성된 그 문맥에서 결정된다. 현대 프로그래밍에서 대부분의 언어들은 렉시컬 스코프 규칙을 따르고 있습니다.
[호이스팅 이란]
호이스팅(Hoisting)을 번역하면 들어올려 나르기, 끌어 올리기로 해석됩니다. 자바스크립트에서 말하는호이스팅도 비슷한 의미로 사용되고 있는데요 아래의 내용을통해 이게 무슨 이야긴지 살펴보도록 하겠습니다.
자바스크립트 함수는 실행되기 전에 함수 안에 필요한 변수값들을 모두 모아서 유효 범위의 최상단에 선언합니다.
자바스크립트 파서(Parser)가 함수 실행 전 해당 함수를 한 번 훑습니다.
함수 안에 존재하는 변수/함수 선언에 대한 정보를 기억하고 있다가 생행시킵니다.
유효범위: 함수 블록 "{}" 안에서 유효
즉, 함수 내에서 아래쪽에 존재하는 내용 중 필요한 값들을 위로 끌어올리는 것입니다. 이러한 모습때문에 호이스팅이라고 부르고있는 것이죠. 단, 실제로는 소스코드가 위로 끌어올려지는 것은 아니며, 자바스크립트 Parser 내부적으로 끌어올려서 처리하는 것이고 실제 메모리 상에서는 변화가 없습니다.
두개의 예시를 통해 호이스팅에 대해 이해를 해보도록 하겠습니다.
function foo() {
a = 2;
var a;
console.log(a);
}
foo();
위의 소스코드를 실행하면 우리가 한눈에 보기에도 문법적으로 문제가 없어보이고, 실행결과 또한 예측한대로 2라는 값이 제대로 출력이 되어질겁니다.
그럼 소스코드상의 순서를 조금 바꿔 아래의 소스코드를 실행시켜 보겠습니다.
function foo() {
console.log(a);
var a = 2;
}
foo();
무언가 선언하지도 않은 변수를 먼저 사용하고 있는 모습에서 부터가 문법적으로 문제가 있어보이는데요.
하지만 var 변수는 앞서 이야기했던 함수 스코프이기 때문에 함수내에서 선언한것은 선언 위치를 기준으로 위에든 아래던간에 사용이 가능합니다.
그렇다면 이 소스코드도 똑같이 2라는 결과값이 나올까요? 대답은 아니오 입니다. 위의 결과로는 undefined 가 출력이 되어지는데요. 이 값은 자바스크립트에서 미리 정의된 상수값이며 의미로는 "선언이 되어있지 않음" 을 의미합니다. 분명 var a = 2 라고 초기화를 했는데 왜 선언이 되어있지 않다고 하는지에 대하여 알아보도록 하겠습니다.
자바스크립트 엔진은 코드를 인터프리팅 하기 전에 그 코드를 먼저 컴파일합니다. var a = 2를 하나의 구문으로 생각하지 않고 다음의 두개 구문으로 분리하여 봅니다.
var a; (선언)
a = 2; (할당=초기화)
변수 선언 단계와 초기화 단계를 나누고, 선언 단계에서는 그 선언이 소스코드의 어디에 위치하든 해당 스코프의 컴파일 단계에서 처리해 버리는 것입니다. 때문에 이런 선언단계가 스코프의 꼭대기로 호이스팅("끌어올림")되는 작업이라고 볼 수 있는 것이죠.
[호이스팅 대상]
이러한 호이스팅이 발생되는 대상에는 무엇이 있을까요?
호이스팅은 var변수 선언과 함수선언문에서만 일어납니다.
var면수/함수의 선언만 위로 끌어 올려지며, 할당은 끌어 올려지지 않는다.
let/const 변수 선언과 함수 표현식에서는 호이스팅이 발생하지 않는다. (var 보단 let 과 const를 사용하자)
함수 표현식이란 익명함수등을 이용한 함수사용을 의미합니다.
[호이스팅의 문제]
호이스팅이 자주 발생하게 된다면 개발자가 코드를 해석하는 가독성이 떨어지게 되고 이는 유지보수의 어려움으로 이어지게 됩니다.
클로저는 내부함수와 밀접한 관계가 있다고 위에서 설명을 드렸는데요, 여기서 내부함수는 외부함수의 지역변수를 가져다 사용이 가능하다 말씀드렸었습니다. 사실 내부함수는 외부함수의 지역변수 뿐 아니라 매개변수값도 참조해서 사용이 가능한데요, 이러한 기능은 창의적인 방법으로 활용될 수 있습니다.
아래의 내부(private)변수예제는 더글라스 크락포드(Douglas Crockford)에 의해 처음 시연되었습니다.
클로저와 객체(Dictionary)를 이용해서 마치 클래스의 Getter 함수, Setter함수와 같은 기능을 하도록 구현이 가능합니다. 이렇게 작성하게 된다면 그저 외부함수 지역변수의 값을 읽어오는것 뿐 아니라 그 값을 변경하는것이 가능해집니다.
또 다른 예제로는 반복문 클로저 예제가 있습니다. 이 예제는 단순히 0~9의 값을 setTimeout 함수를 이용해 출력하는 함수를 구현하는 것입니다. 만약 클로저를 고려하지 않고 이를 구현하라고 한다면 아래와 같이 작성을 하게 될것입니다.
하지만 이렇게 작성된 코드의 결과는 우리가 예상했던 0~9의 값을 출력하는 것이 아니라 10의 값을 반복해서 찍어주게 됩니다.
이유즉슨, setTimeout 함수에 인자로 넘어간 익명함수는 모두 0.1초 뒤에 호출이 되어지게 될텐데 그 시간 사이에 반복문이 전부 돌아 i값을 10으로 만들어 버렸기 때문입니다.
이를 우리가 원했던 0~9의 값이 출력되도록 하기 위해서는 클로저를 이용하여 매 반복시 증가되는 i값을 매개값으로 받는 외부함수 하나를 생성하고 그안에서 i값을 받아 setTimeout을 실행하는 내부함수를 만들어 주면 됩니다.
이렇게 해주게 되면, 외부함수를 반복횟수만큼 실행한 상황이 만들어지고 각 외부함수 매개값으로 i값을 넘겨주었기 때문에 이를 내장함수가 참조해서 사용할 수 있게 되어지는 것이죠.
자바스크립트에서는 함수가 선언될 때 자신이 접근할 수 있는 범위를 정하고 기억하고 있는데 이것을 렉시컬 스코프라고 합니다. 그리고 이런 렉시컬 스코프에 의해 외부 함수의 환경을 기억하고 있는 내부 함수가 클로저입니다.
여기서 "lexical"이란, 어휘적 범위 지정(lexical scoping) 과정에서 변수가 어디에서 사용 가능한지 알기 위해 그 변수가 소스코드 내 어디에서 선언되었는지 고려한다는 것을 의미합니다. 단어 "lexical"은 앞에서 정의한 의미를 가지며, 중첩된 함수는 외부 범위(scope)에서 선언한 변수에도 접근할 수 있습니다.
클로저는 클래스와 꽤나 비슷한 구조를 가지고 있습니다. 그렇기 때문에 클래스 개념이 없는(ES6에서는 있습니다.) 자바스크립트에서는 클래스를 대신하여 쓰이기도 합니다.
그렇다면 객체지향적 개발을 위해서 클로저를 무조건 사용하는것이 좋을까요?
그에대한 대답은 "적절한 상황에 사용하되 메모리할당을 해제시켜주자" 라고 답변드리고 싶습니다.
클로저는 각자의 환경을 가집니다. 이환경을 기억하기 위해서 외부함수자체를 소멸시키지 않고 기억하기 때문에 당연히 메모리 또한 소모되어질겁니다. 그렇기 때문에 클로저를 생성해놓고 참조를 제거하지 않는 것은 C++에서 동적할당으로 객체를 생성해놓고 메모리할당을 해제하지 않는것과 비슷합니다.
즉, 클로저를 통해 내부 변수를 참조후 사용이 끝나면 참조를 제거하는것이 메모리 효율에 좋다고 볼 수 있습니다.
요약하자면, 유저를 대신해 서버로부터 데이터를 보내거나 받아주고 또, 받아온 정보(데이터)를 GUI를 통해서 유저에게 보여주는 존재입니다.
여기서 우리가 알아볼 정보는 총 세가지 입니다.
브라우저는 데이터를 어떻게 받아 오는가?
브라우저는 데이터를 어떻게 전송하는가?
브라우저는 서버로부터 받아온 데이터를 화면에 어떤 방식으로 렌더링하는가?
차근차근 하나씩 공부하여 알아보도록 하겠습니다.
🐵 브라우저는 데이터를 어떻게 주고 받는가?
기본적으로 우리가 브라우저를 이용하여 서버와 데이터를 주고 받을때에는 HTTP라는 통신규약(프로토콜)을 이용하여 받아오게 됩니다.
(여기서 프로토콜이 무엇인지는 언급하지 않겠습니다)
그렇다면 HTTP를 통해 데이터를 받아오는 과정은 어떨까요?
서버와 브라우저가 데이터를 주고 받기는 이 과정을 Request(요청) 과 Response(응답)이라고 표현합니다. 이러한 방식을 Client-Server 방식이라고 부르는데요, 즉 서버에게 나 "~이런정보가 필요해 혹은 가져왔으니 받아줘" 라는 Request(요청)을 하면 서버가 요청을 이해하고 그에 알맞는 Response(응답)을 해주는 것입니다.
여기서 우리의 요청이 특정 서버에게 잘 도착하게 하기 위해서 브라우저의 URL에 해당 서버의 IP 주소 혹은 도메인 네임을 적어서 요청하게 됩니다. 그러면 우리의 컴퓨터(운영체제)는 일종의 요청서에 해당하는 Packet이라는 데이터를 만들어 그 안에 도착지(서버주소)와 자신의 IP주소를 적어 라우터에게 전달하게 됩니다.
(여기서부터 서버까지 도달하는 일은 라우터가 우리가 만든 해당 Packet을 해석해서 알아서 전달해주게 됩니다.)
(사실 이과정에서 바로 데이터를 보내주는것이 아니라 3Hand Shake라는 과정을 거쳐 서로가 네트워크 연결이 잘 되어있는지 확인하는 절차를 거친 후에 데이터를 주고 받습니다.)
🐵 브라우저 렌더링 방법은?
렌더링이란 논리적인 문서의 표현식을 그래픽 표현식으로 변형시키는 과정입니다. 즉 브라우저 렌더링은 서버로부터 받은 문서 혹은 파일을 그래픽 표현식으로 변형시켜주는 과정이라 볼 수 있겠습니다.
여기서 브라우저가 어떻게 렌더링을 하는것인가를 알아보기 전에 브라우저가 어떤 구조로 되어있는지 부터 알아보고 이야기를 시작하도록 하겠습니다.
브라우저는 아래의 내용으로 구성되어있습니다.
사용자 인터페이스 - 주소 표시줄, 이전/다음 버튼, 북마크 메뉴 등. 요청한 페이지를 보여주는 창을 제외한 나머지 모든 부분이다.
브라우저 엔진 - 사용자 인터페이스와 렌더링 엔진 사이의 동작을 제어.
렌더링 엔진 - 요청한 콘텐츠를 표시. 예를 들어 HTML을 요청하면 HTML과 CSS를 파싱하여 화면에 표시함.
통신 - HTTP 요청과 같은 네트워크 호출에 사용됨. 이것은 플랫폼 독립적인 인터페이스이고 각 플랫폼 하부에서 실행됨.
UI 백엔드 - 콤보 박스와 창 같은 기본적인 장치를 그림. 플랫폼에서 명시하지 않은 일반적인 인터페이스로서, OS 사용자 인터페이스 체계를 사용.
자바스크립트 해석기 - 자바스크립트 코드를 해석하고 실행.
자료 저장소 - 이 부분은 자료를 저장하는 계층이다. 쿠키를 저장하는 것과 같이 모든 종류의 자원을 하드 디스크에 저장할 필요가 있다. HTML5 명세에는 브라우저가 지원하는 '웹데이터베이스'가 정의되어 있다.
아래의 사진을 보면 더 이해가 잘될텐데요,
(Naver D2 페이지에서 발췌한 사진입니다.)
Naver D2 페이지에서 발췌
즉 우리가 더 깊게 알아봐야할 부분이 렌더링 엔진! 이라는 겁니다. 브라우저가 "렌더링 엔진" 이라는 것을 이용해 렌더링을 수행하는 것인거죠.
렌더링 엔진
그럼 렌더링 엔진에 대하여 알아보겠습니다.
렌더링 엔진의 종류에는 파이어폭스를 만든 모질라에서 직접 제작한 게코엔진과 사파리와 크롬에서 사용되어지고 있는 웹킷엔진이 있습니다.
이러한 렌더링 엔진의 역할은 요청 받은 내용을 브라우저 화면에 표시하는 일입니다.
여기서 요청받아 표시하는 정보들에는 HTML, CSS, JS들이 있고 플러그인이나 브라우저 확장 기능을 이용해 PDF와 같은 다른 유형도 표시가 가능합니다.
자 이제 렌더링 엔진이 동작하는 과정을 살펴보겠습니다.
렌더링엔진은통신으로부터 요청한 문서의 내용을 얻는 것으로 시작하는데 문서의 내용은 보통8KB 단위로 전송되어집니다.
웹 브라우저가 원본 HTML 문서를 읽어들인 후, 스타일을 입히고 대화형 페이지로 만들어 뷰 포트에 표시하기까지의 과정을 “Critical Rendering Path”라고 합니다. Understanding the Critical Rendering Path 에서 다루듯이 이 과정은 여러 단계로 나누어져 있지만, 이 단계들을 대략 두 단계로 나눌 수 있습니다.
첫 번째 단계에서 브라우저는 읽어들인 문서를 파싱하여 최종적으로 어떤 내용을 페이지에 렌더링할지 결정합니다.
렌더링 엔진은 위에서 언급한 첫 번째 단계에 해당하는 HTML 문서를 파싱을 하고 "콘텐츠 트리"(DOM트리) 내부에서 태그를DOM노드로 변환합니다.
그 다음 외부 CSS 파일과 함께 포함된 스타일 요소도 파싱하는 과정을 거칩니다.
[렌더 트리 구축]
이때, 스타일 정보와 HTML 표시 규칙은 "렌더트리"라고 부르는 또 다른 트리를 생성하게 됩니다.
렌더 트리는 색상 또는 면적과 같은 시각적 속성이 있는 사각형을 포함하고 있는데 정해진 순서대로 화면에 표시됩니다.
[렌더 트리 배치]
렌더 트리 생성이 끝나면 배치가 시작되는데 이것은 각 노드가 화면의 정확한 위치에 표시되는 것을 의미합니다.
다음은 UI 백엔드에서 렌더 트리의 각 노드를 가로지르며 형상을 만들어 내는 그리기 과정입니다.
일련의 과정들이 점진적으로 진행된다는 것을 아는 것이 중요합니다. 렌더링 엔진은 좀 더 나은 사용자 경험을 위해 가능하면 빠르게 내용을 표시하는데 모든 HTML을 파싱할 때까지 기다리지 않고 배치와 그리기 과정을 시작합니다. 네트워크로부터 나머지 내용이 전송되기를 기다리는 동시에 받은 내용의 일부를 먼저 화면에 표시하는 것입니다.
아래의 사진은 렌더링 엔진 별 동작과정을 나타낸 이미지입니다.
(Naver D2페이지에서 발췌)
웹킷 동작 과정모질라의 게코 렌더링 엔진 동작 과정
웹킷과 게코가 용어를 약간 다르게 사용하고 있지만 동작 과정은 기본적으로 동일하다는 것을 위의 그림들을 통해 알 수 있습니다.
게코는 시각적으로 처리되는 렌더 트리를 "형상 트리(frame tree)"라고 부르고 각 요소를 형상(frame)이라고 하는데 웹킷은 "렌더 객체(render object)"로 구성되어 있는 "렌더 트리(render tree)"라는 용어를 사용합니다. 웹킷은 요소를 배치하는데 "배치(layout)" 라는 용어를 사용하지만 게코는 "리플로(reflow)" 라고 부릅니다. "어태치먼트(attachment)"는 웹킷이 렌더 트리를 생성하기 위해 DOM 노드와 시각 정보를 연결하는 과정입니다.